ACTIV-ES corpus: initial release
corpora
spanish
projects
ACTIV-ES: a comparable, cross-dialect corpus of ‘everyday’ Spanish from Argentina, Mexico, and Spain
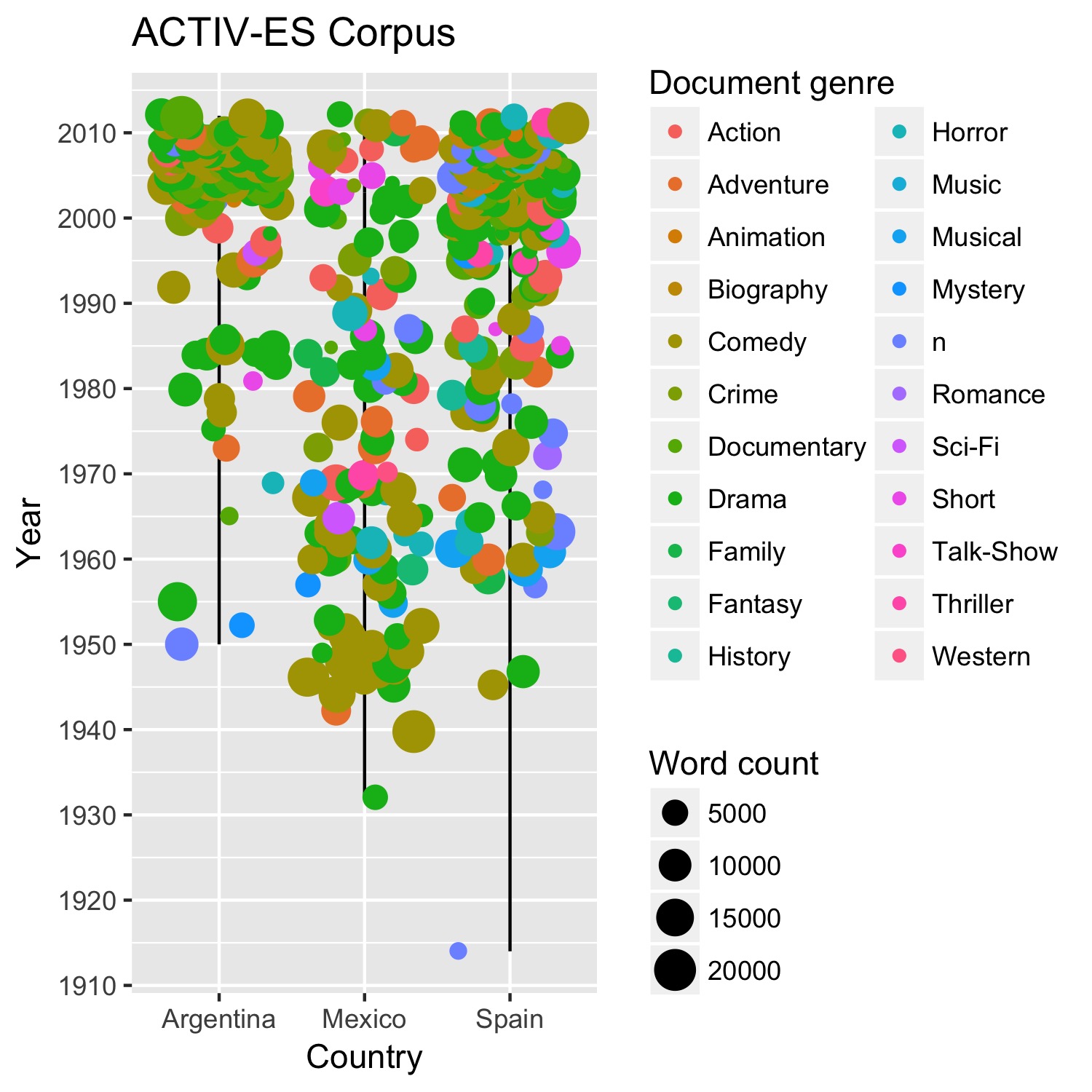
The first release of the ACTIV-ES Spanish dialect corpus based on TV/film transcripts is now available on GitHub.
It includes 3,460,172 total tokens (Argentina: 1,103,039 Mexico: 976,192 Spain: 1,380,941) and comes in running text and word list (1:5 gram) formats. Each format has both a plain text and part-of-speech tagged version.
For more information about the development and evaluation of this resource you can download our paper “ACTIV-ES: a comparable cross-dialect corpus of everday Spanish from Argentina, Mexico, and Spain” at the Ninth Annual Language Resources and Evaluation Conference (LREC 2014)
Citation
BibTeX citation:
@online{francom2014,
author = {Francom, Jerid},
title = {ACTIV-ES Corpus: Initial Release},
date = {2014-05-24},
url = {https://francojc.github.io/posts/actives-corpus-initial-release/},
langid = {en}
}
For attribution, please cite this work as:
Francom, Jerid. 2014. “ACTIV-ES Corpus: Initial Release.”
May 24, 2014. https://francojc.github.io/posts/actives-corpus-initial-release/.